

昨年11月の「チャットGPT」公開以来、生成AIに対する関心が高まっている。政府は生成AIについて「デジタル化・デジタル技術の活⽤を加速させ、我が国全体の⽣産性向上のみならず、様々な社会課題解決に資する可能性がある」(AI戦略会議・暫定的な論点整理)と位置付けた。
日本経済が直面する少子高齢化、低成長などの課題の解決に向けて、生成AIの力を引き出すため、避けて通れないのが日本語による回答・作業・分析の精度の向上である。
日本語での精度が低い理由
2023年6月現在、一般公開されている主要な生成AIに対し、日本語で質問した場合、不正確な答になることがある。人名について尋ねると、別人について回答し、為替の変動について尋ねると、通貨安と通貨高を取り違えるといった具合である。
日本語による質問、作業の精度が英語に比べると必ずしも高くはないのはなぜか。問題は、集積されたデータの量にある。
チャットGPTに代表される有力な生成AIは、大規模言語モデル(LLM)を用い、インターネット上の文献やデータを読み込んだうえ、確率的に高い単語を連ね、文章を創出する。開発している企業、研究機関の方針に基づき、データ・利用頻度が多い英語や中国語が有力な学習対象となっており、日本語の学習量は相対的に少ない。
主だった生成AIは、日本語を含む多様な言語への対応を進めているものの、学習・サービス提供時に集まるデータの量は英語が他の言語を圧倒している。データ量の差が日本語での回答や作業の精度の低さにつながっている。
さらに、生成AIの一部は、日本語で回答する際、システムの裏側では学習結果を処理している。英語でデータを処理・分析した上、アウトプットの段階で利用者に合わせて日本語に翻訳している格好だ。
例えば、生成AIに日本語で「境(さかい)さん」という人物について尋ねた場合、現状では「Sakai」という英語データが相当程度、反映されている。アルファベットでは同じ「Sakai」で表記される「堺さん」「酒井さん」などのデータが「境さん」に混ざり、誤った回答になるような事例である。こうしたシステム内部の翻訳処理も精度に関する課題につながっている。
活用の遅れ、成長に影響
このように日本語での精度が低い状況を放置した場合、どのような問題が生じるのだろうか。
短期間に表面化する問題は、日本の企業や社会での活用の遅れである。生成AIをビジネスや社会活動に用いる場合、少ないストレスで対話できるかどうかが普及の焦点となる。日本語での精度が低いままであれば、利便性の向上は見込めず、英語圏と比べて普及が遅れる事態となる。
日本語での精度の低さや活用の遅れは、中長期的には日本の産業の成長力に影響を与えかねない。米国の大学による実験では、生成AIを使った場合、文書作成や調査、分析などの作業時間が短縮され、品質も向上し、生産性の向上につながることが示された。
日本の企業、ビジネスにとって、生成AIの導入が進むかどうかが、今後数年~十数年の生産性向上を左右する可能性がある。日本語版生成AIの精度が改善しなければ、日本のビジネスでのAI活用の質と範囲が英語圏よりも劣後し、日本の企業・産業の成長の制約になる恐れがある。
さらに、政府内には、海外製AIへの依存が進んだ場合、非常時に供給途絶の危険性が高くなるとの懸念がある。現時点で日本のAI開発、サービスは海外企業に対する依存度が高く、日本企業にとってはAI利用に伴う費用増加や情報流出、サービスの停止・縮小がリスクとなる。
開発と利用促進が焦点
それでは、日本語での精度を向上させるには、どのような取り組みが求められるのだろうか。整理すると、次の2点がポイントになる。
- 日本語ベースの生成AIの開発強化
- 日本語での利用促進(需要・市場拡大)
前者の日本語ベースでの生成AIの開発強化については、政府が成長戦略2023改訂版で政策課題に挙げており、企業や研究機関が取り組みを始めている。今年5月には、国立大学や研究所、デジタル企業がスーパーコンピューター「富岳」を使ったLLMの構築に乗り出すと発表した。日本語の大規模なデータの集積や、特有の表現の学習を通じて、生成AIの精度を高めていくことが期待されている。
ただし、現状では、生成AIの複雑さを表し、性能を左右する「パラメータ数」(AIが学習時に最適化する必要のある変数の数)は、米国のAI企業やプラットフォーマーなどが開発するモデルが日本企業のモデルを凌駕している。(表)
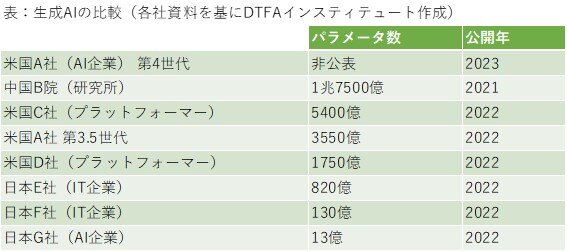
前述の供給途絶リスクを考慮に入れれば、国内開発を進める重要性はあるものの、高性能の海外モデルの日本語版の精度向上を働きかけていくことが、現実的かつ必要な対応になるだろう。
それには、国内だけではなく海外の開発企業にも、使いやすい日本語データを提供し、生成AIが学習しやすい環境を整えることが欠かせない。同時に、日本語での生成AI利用を促進し、AIビジネスにとっての日本の市場の魅力を高めることが求められる。
特に、生成AIはビジネスだけではなく、医療、介護、教育などの現場で課題を解決することが期待されている。個人情報の保護や虚偽の拡散抑制といったリスク対策を十分に講じることを前提としたうえで、AI専門家ではない老若男女が生成AIを使いやすい環境を整えていくことが重要である。活用の幅が広がれば、新たなAI市場・事業が生まれる可能性がある。その結果、日本市場への期待が高まり、日本語版の精度が向上し、さらに普及するという好循環を創出できるかもしれない。
生成AI普及が進む中、企業はどのようにビジネスに活用していくのかを問われる。次回のレポートではAIガバナンス構築を含む留意点について取り上げたい。
<参考資料>
「新しい資本主義のグランドデザイン及び実行計画2023改訂版」、2023年6月16日閣議決定
政府AI戦略会議「AIに関する暫定的な論点整理」、2023年5月26日
Shakked Noy and Whitney Zhang. ” Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence” Working paper, March 6, 2023.
